(Sliced) Wasserstein - Gaussian process regression workflow
Source:vignettes/sliced-wasserstein-workflow.Rmd
sliced-wasserstein-workflow.RmdGoal
This vignette illustrates the main use of the slicer
package by means of a toy example. Empirical distributions are generated
from bivariate Gaussian mixtures with four isotropic components laid out
symmetrically around the origin. These distributions differ from one
another in that they are rotated counterclockwise by an angle
.
The goal of the analysis is to retrieve the specific angles by which the
distributions have been rotated.
Functions
Let’s load slicer.
To generate the input distributions, we define
generate_data():
generate_data <- function(n = 200, a = 5, angle = 0, Sigma = diag(1, 2)) {
mus <- cbind(c(a, 0), c(0, a), c(-a, 0), c(0, -a))
R <- rbind(
c(cos(angle), -sin(angle)),
c(sin(angle), cos(angle))
)
cluster <- sample(1:4, size = n, replace = TRUE)
d <- matrix(0, nrow = n, ncol = 2)
for (i in 1:4) {
d[which(cluster == i), ] <- MASS::mvrnorm(
sum(cluster == i), mu = mus[, i], Sigma = Sigma
)
}
d %*% t(R)
}The plots below show two empirical distributions, once using a rotation angle of and once using one of .
set.seed(2026) # for reproducibility
op <- par(no.readonly = TRUE)
par(mfrow = c(1, 2))
generate_data(angle = pi/16) |>
plot(xlab = "first dimension", ylab = "second dimension", asp = 1)
generate_data(angle = 3*pi/8) |>
plot(xlab = "first dimension", ylab = "second dimension", asp = 1)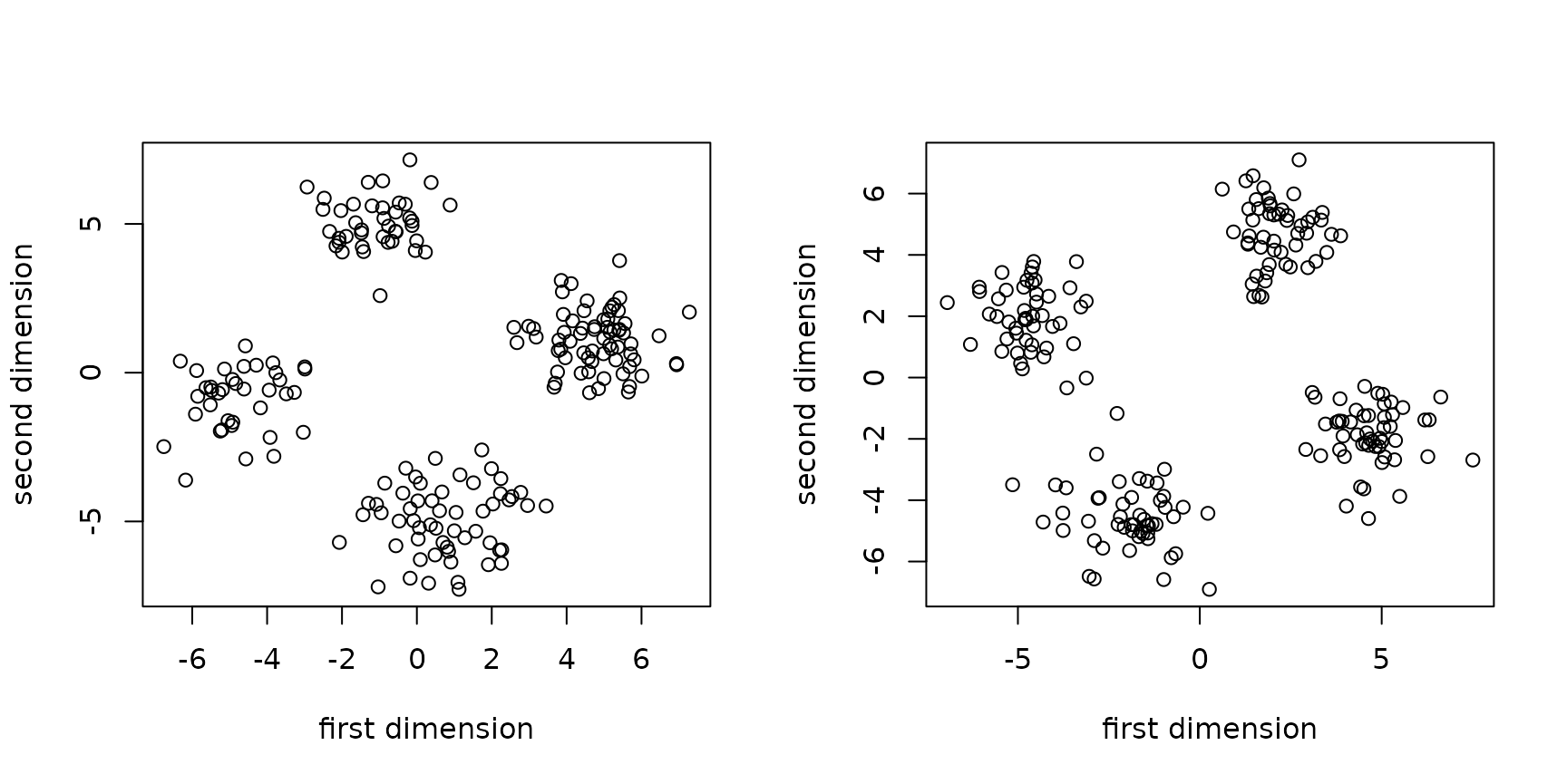
par(op)Finally, a function for computing the root mean squared error of the predictions:
Data generation
We generate 60 matrices (40 for training, 20 for testing) containing empirical distributions with the rotation angles sampled uniformly from . Each empirical distribution is based on 200 data points.
Distances
We can use compute_all_distances() to compute pairwise
distances between the input distributions. If we supply the optional
vector test_idx with the test set indices, the pairwise
distance computations between test objects (which are not needed) are
skipped. To compute sliced Wasserstein distances, we
need to first generate
sampled uniformly at random from the unit sphere;
generate_directions() takes care of this. We’ll use
and set
since we’re working in two dimensions. If we’re only interested in the
estimated sliced Wasserstein distances, we can set
keep_projections to FALSE.
thetas <- generate_directions(L = 25, d = 2)
sw_distances <- compute_all_distances(distributions, thetas, verbose = FALSE,
keep_projections = FALSE, test_idx = N_train + seq_len(N_test))The
matrix sw_distances contains the squared
(estimated) sliced Wasserstein distances among the forty training
objects and between the training objects and the twenty test objects.
The pairwise distances among the test objects are set to
NA.
We can also compute (normal) Wasserstein distances
between the distributions when they are projected along certain
dimensions. For instances, to compute the pairwise Wasserstein distances
along the first margin and along the second margin, we set the
projection directions to
and
.
We also set keep_projections = TRUE, which will cause the
function to output a list of two matrices with squared
Wasserstein distances: one for each margin.
marginal_distances <- compute_all_distances(distributions, diag(1, 2),
verbose = FALSE, keep_projections = TRUE,
test_idx = N_train + seq_len(N_test))
str(marginal_distances)
#> List of 2
#> $ : num [1:60, 1:60] 0 1.274 0.931 0.548 0.649 ...
#> $ : num [1:60, 1:60] 0 2.177 0.121 0.445 0.599 ...Gaussian process models with tuned hyperparameters
The function fit_gpr() takes a single matrix with
squared pairwise distances and uses it as input to a Gaussian process
regression model with a Gaussian RBF kernel. The model’s and the
kernel’s hyperparameters are tuned using the training data by minimising
the negative marginal log-likelihood.
sw_fit <- fit_gpr(sw_distances,
training_idx = seq_len(N_train),
test_idx = N_train + seq_len(N_test),
y_train = angles[seq_len(N_train)],
verbose = TRUE)
#> Hyperparameter search 1 of 10.
#> Optimum set at -58.8175077.
#> Hyperparameter search 2 of 10.
#> Hyperparameter search 3 of 10.
#> Hyperparameter search 4 of 10.
#> Hyperparameter search 5 of 10.
#> Hyperparameter search 6 of 10.
#> Hyperparameter search 7 of 10.
#> Hyperparameter search 8 of 10.
#> Current optimum improved from -58.8175077 to -58.8176617.
#> Hyperparameter search 9 of 10.
#> Hyperparameter search 10 of 10.The output consists of predictions for the test data, the root mean squared error of these predictions (if the true test outcomes were provided), and the estimated hyperparameters.
str(sw_fit)
#> List of 7
#> $ test_predictions: num [1:20] 0.241 0.7091 0.2402 0.5074 0.0604 ...
#> $ test_variance : num [1:20, 1:20] 0.00134 NA NA NA NA ...
#> $ RMSE : logi NA
#> $ length_scale : num 1.57
#> $ scaling_factor : num 0.0758
#> $ noise_variance : num 1.57e-07
#> $ nll : num -58.8
plot(angles[N_train + seq_len(N_test)], sw_fit$test_predictions,
xlab = "true test outcomes", ylab = "predicted test outcomes", asp = 1)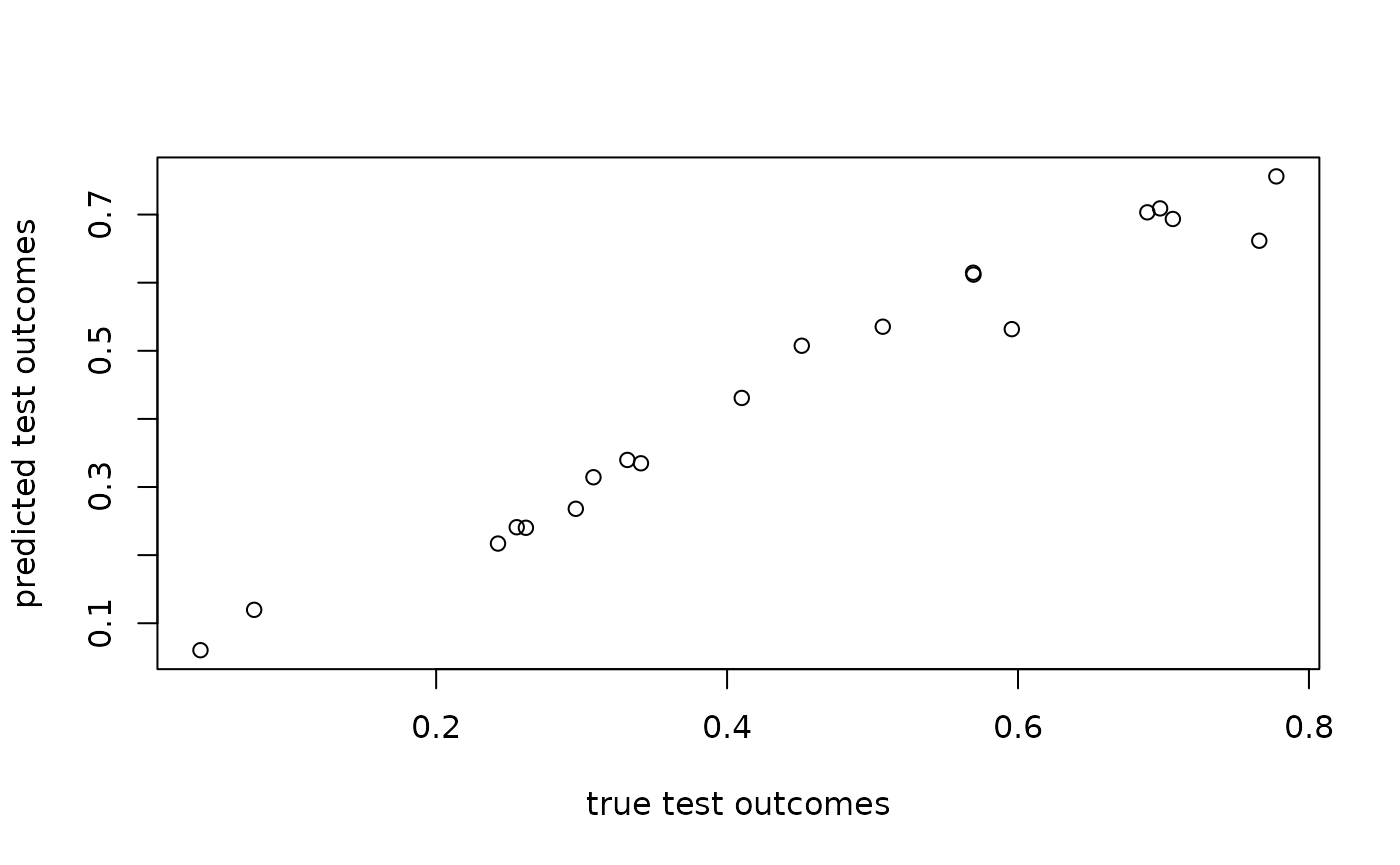
rmse(sw_fit$test_predictions, angles[N_train + seq_len(N_test)])
#> [1] 0.03804247The function fit_gpr() can also be used when multiple
matrices with squared distances are provided. Now, estimated
length-scale and (kernel) variance hyperparameters are provided for the
Gaussian RBF corresponding to each squared distance matrix.
marginal_fit <- fit_gpr(marginal_distances,
training_idx = seq_len(N_train),
test_idx = N_train + seq_len(N_test),
y_train = angles[seq_len(N_train)],
verbose = TRUE)
#> Hyperparameter search 1 of 10.
#> Optimum set at -48.3151392.
#> Hyperparameter search 2 of 10.
#> Current optimum improved from -48.3151392 to -61.5134707.
#> Hyperparameter search 3 of 10.
#> Hyperparameter search 4 of 10.
#> Hyperparameter search 5 of 10.
#> Hyperparameter search 6 of 10.
#> Hyperparameter search 7 of 10.
#> Hyperparameter search 8 of 10.
#> Current optimum improved from -61.5134707 to -61.5134707.
#> Hyperparameter search 9 of 10.
#> Hyperparameter search 10 of 10.
str(marginal_fit)
#> List of 7
#> $ test_predictions: num [1:20] 0.2395 0.6678 0.2429 0.5619 0.0919 ...
#> $ test_variance : num [1:20, 1:20] 0.000587 NA NA NA NA ...
#> $ RMSE : logi NA
#> $ length_scale : num [1:2] 3.9 6.09
#> $ scaling_factor : num [1:2] 0.347 0.146
#> $ noise_variance : num 0.000448
#> $ nll : num -61.5
plot(angles[N_train + seq_len(N_test)], marginal_fit$test_predictions,
xlab = "true test outcomes", ylab = "predicted test outcomes", asp = 1)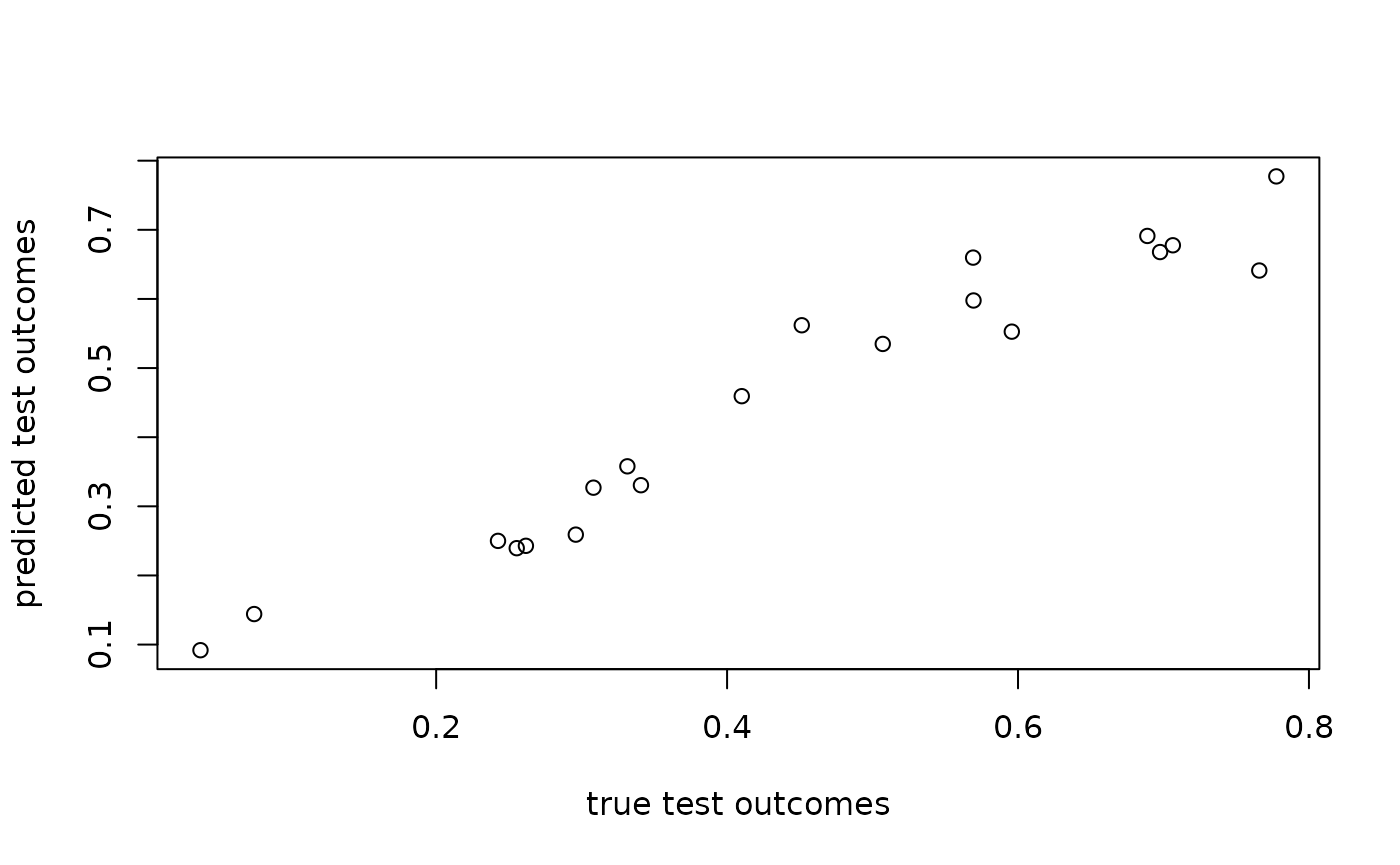
rmse(marginal_fit$test_predictions, angles[N_train + seq_len(N_test)])
#> [1] 0.05219439We can combine the marginal and sliced Wasserstein distances into a list with three distance matrices, too:
total_fit <- fit_gpr(list(sw_distances, marginal_distances[[1]], marginal_distances[[2]]),
training_idx = seq_len(N_train),
test_idx = N_train + seq_len(N_test),
y_train = angles[seq_len(N_train)],
verbose = TRUE)
#> Hyperparameter search 1 of 10.
#> Optimum set at -58.8320454.
#> Hyperparameter search 2 of 10.
#> Current optimum improved from -58.8320454 to -61.5129334.
#> Hyperparameter search 3 of 10.
#> Current optimum improved from -61.5129334 to -63.080251.
#> Hyperparameter search 4 of 10.
#> Hyperparameter search 5 of 10.
#> Hyperparameter search 6 of 10.
#> Hyperparameter search 7 of 10.
#> Hyperparameter search 8 of 10.
#> Hyperparameter search 9 of 10.
#> Hyperparameter search 10 of 10.
str(total_fit)
#> List of 7
#> $ test_predictions: num [1:20] 0.247 0.69 0.247 0.549 0.085 ...
#> $ test_variance : num [1:20, 1:20] 0.00081 NA NA NA NA ...
#> $ RMSE : logi NA
#> $ length_scale : num [1:3] 0.421 3.833 5.482
#> $ scaling_factor : num [1:3] 0.00118 0.24703 0.12446
#> $ noise_variance : num 3.32e-08
#> $ nll : num -63.1
plot(angles[N_train + seq_len(N_test)], total_fit$test_predictions,
xlab = "true test outcomes", ylab = "predicted test outcomes", asp = 1)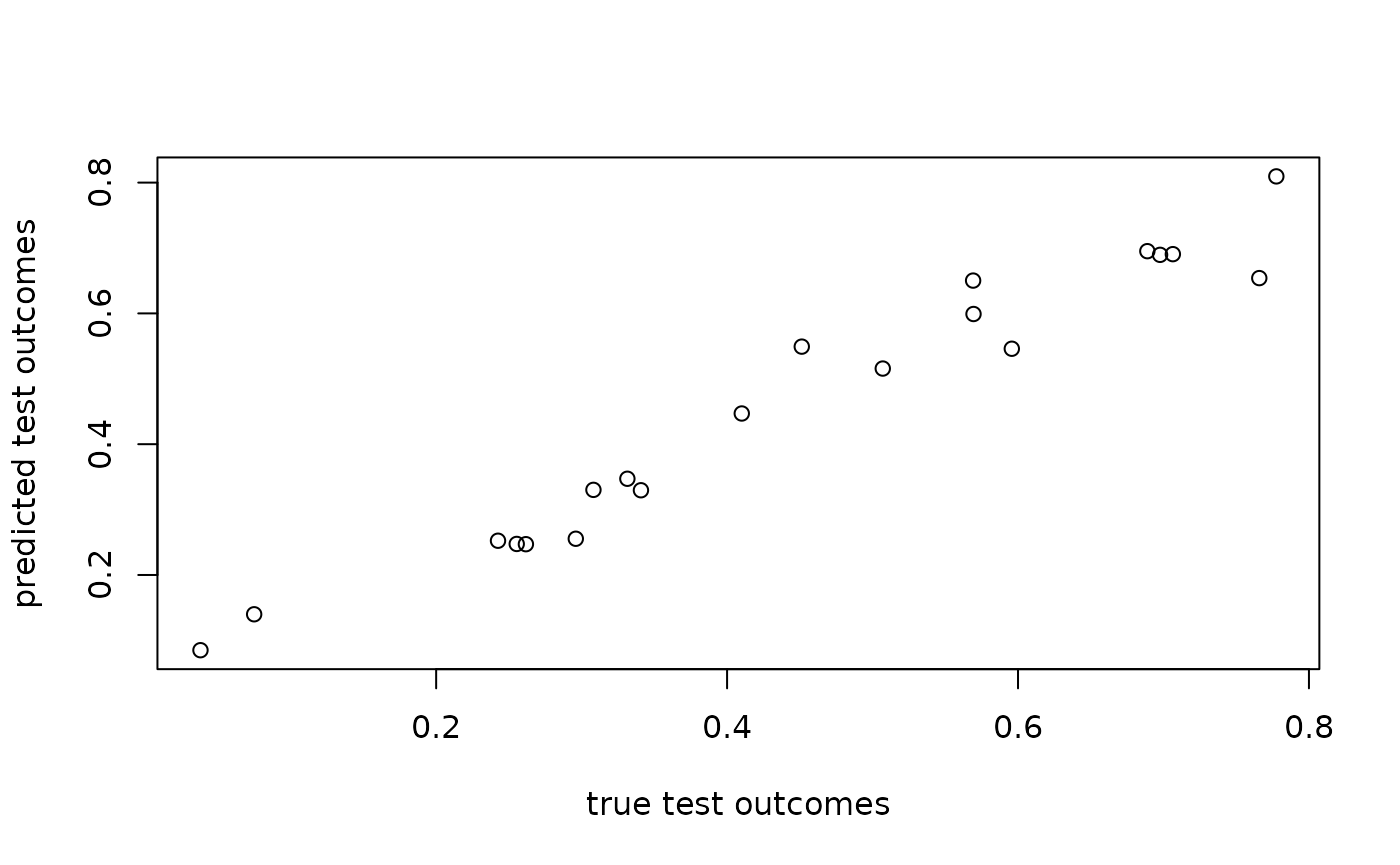
rmse(total_fit$test_predictions, angles[N_train + seq_len(N_test)])
#> [1] 0.04697571Parallel processing can be enabled using the cores
parameter:
total_fit <- fit_gpr(list(sw_distances, marginal_distances[[1]], marginal_distances[[2]]),
training_idx = seq_len(N_train),
test_idx = N_train + seq_len(N_test),
y_train = angles[seq_len(N_train)], runs = 50L, cores = 2L)
str(total_fit)
#> List of 7
#> $ test_predictions: num [1:20] 0.247 0.69 0.247 0.549 0.085 ...
#> $ test_variance : num [1:20, 1:20] 0.00081 NA NA NA NA ...
#> $ RMSE : logi NA
#> $ length_scale : num [1:3] 0.421 3.836 5.49
#> $ scaling_factor : num [1:3] 0.00118 0.24758 0.12478
#> $ noise_variance : num 5.2e-08
#> $ nll : num -63.1